Compressing Chess Moves Even Further, To 3.7 Bits Per Move
Chess moves in standard notation take 16 to 56 bits. How low can we go?I wrote a post yesterday about how to compress chess
moves. I was pretty happy with my hand-rolled compression scheme, which
achieved a per-move size of 9.5 bits. I almost just rolled with it, but I've
been thoroughly nerd-sniped here, so I took another crack at it.
To know the board state or not
One of the main considerations in compressing chess moves is how much
chess-specific computation you want to do. One of the most optimal forms of
compression is actually to evaluate the position, use an engine
like Stockfish, and then store the index of the move. This isn't really a
viable method though, the CPU cost is insane. But that's just to highlight what
one end of the spectrum looks like.
The other end of the spectrum is what I was
doing with my hand-rolled compression, which required zero knowledge of the
board state. I thought that move generation was going to be too expensive, and
I didn't want to jump from being IO-bound to being CPU-bound. But then I ran
some speed tests, and found that the chess library I'm using, Shakmaty, is
insanely fast and would definitely not be a bottleneck.
The starting point
The starting point for this new method was Lichess' genius approach to encoding
moves efficiently. You can read more about that approach
here.
The general idea is this:
- Generate the legal moves in a position
- Order those moves using some fast, simple heuristics, like if it's a
promotion score it really highly, since when that's a legal move it's almost
always played - Store the index of the move
If you were just storing indexes, this would be 8 bits per move (maximum # of
legal moves appears to be 219 or so). But the point of ordering is that you can
then encode some symbols with shorter codes than others. For example the index
0 could be only a couple bits, where maybe the 200th index is 12 bits.
This is an incredibly smart approach while still being fairly simple to
implement. In taking a similar tack for Chessbook, I came up with some tweaks.
Some are generally applicable, some are specific to my situation.
Arithmetic coding instead of Huffman
The Lichess approach used Huffman codes, which are great, but arithmetic coding
has one big advantage; it can represent symbols using a fractional number of
bits. The math is a bit over my head to be perfectly hoest, but in practice I
saw about a 10% size reduction by using arithmetic coding instead of Huffman
coding.
Opening-specific piece square tables
Lichess uses a piece square table to encode the opening. I originally tried
using their same piece square tables. There seemed to be a lot of easy wins to
be had by adjusting the tables manually. For example, g3 is a common opening
move, but it had no weight in the pawn square table, so it wasn't ranking high
enough.
I have to note at this point that my use case is compressing a ton of opening
lines, the Lichess piece tables may be perfect for compressing entire games. We
have different needs.
I didn't want to be hand-tweaking piece square tables though. So I wrote a loop
which would modify a couple different piece square table values by [-15,15],
and then test to see if that tweak resulted in a better score. If it did, it
would keep the change, otherwise it reverted to the old values.
I ran this about 100,000 times on a representative sample of 10,000 of opening
lines, and eventually arrived at the "perfect" piece square table values for my
use case, as it's been running for another 1,000 iterations and hasn't found
any further improvements. At least, it's a local maxima. There's probably a
fancier way here to find a global maxima, maybe using something like simulated
annealing. I'm not smart enough for that though, and I expect the global maxima
isn't substantially higher.
Other ranking algorithm tweaks
In the original Lichess post they had a couple manual additions:
- Prefer captures if available
- Prefer promotions if available
- Don't move any pieces to a square defended by a pawn
I found these to be a bit too cut-and-dry, so I made some tweaks that worked for my use-case.
Captures
For captures, instead of just sorting any capture to the top, I assign a
capture a value of the same magnitude of the piece square tables, 6 if the
piece is of the same value (i.e. a pawn capturing a pawn), or 5 times the
difference in piece value (i.e a pawn capturing a queen would get a score of(9-1)*5=40 ) if they're different pieces.
Pawn-defended squares
A lot of very common opening moves which put a pawn on a square defended by
another pawn were being down-weighted. This probably makes sense as a hueristic
for every piece besides pawns, but for pawns it's very common to "contest"
another pawn. So I adjsuted this logic to only down-weight moves to a
pawn-defended square, for pieces that aren't pawns.
Thoughts on further improvements
Some scattered ideas for further improvements:
- Some hard-coded opening-specific knowledge would probably go a long way, while not consuming too much memory/CPU cycles. This is getting a bit too meta for me though.
- Probably I don't need to support encoding for up to the theoretical maximum number of moves, and something like 128 moves would be fine. It's a bit risky though, and I think the difference would be pretty small.
Other than those small tweaks I'm sort of out of ideas. I think I've taken this
as far as I'll be able to.
More blog posts by marcusbuffett
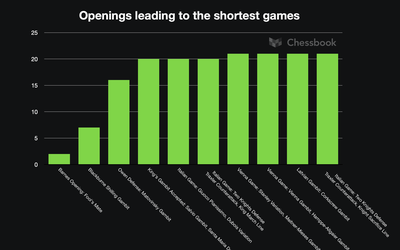
Which openings lead to the shortest games? What about the longest games?
I thought it would be sort of interesting to see which openings lead to the shortest games and which…